Block allocation strategies of various filesystems
How do filesystems behave if you overwrite a file multiple times? One may
think they use up to 1 or 2 times the file's size plus some constant overhead.
To be sure I set up a small virtual machine inside a VMware ESXi host. The
virtual machine had 1 vCPU, 1 GB of ram, an Intel e1000 network card, and a
LSI Logic parallel scsi controller. For each test the virtual machine was
rebooted and assigned a fresh 20 GB thin provisioned disk. Then a partition
and the filesystem were created. After mounting the filesystem I used
dd to write 100 MB of null data to a file and noted the actual size
of the virtual disk by executing du on the ESXi server. Then I wrote
again 100 MB to the same file and again noted the virtual disk's size. This
was done 300 times for each filesystem I tested. These are ext4, ext3, ext2,
xfs, btrfs, and ufs2.
With the exception of ufs2 I booted a Gentoo install cdrom image
(install-amd64-minimal-20120621.iso) which comes with a Linux kernel
3.4.9. The btrfs tools were copied from another running Gentoo box. For ufs2 I
installed a minimal FreeBSD 9.0 amd64 on another disk and deactivated all
unneccessary daemons which are enabled by default (cron, syslogd, sendmail).
All filesystems were created with their default values.
Updated 2012-09-05: I installed Windows 2008 R2 and tested NTFS. The
virtual machine was upgraded to 4 GB ram for that.
First, I tested ext4, ext3, ext2, xfs, and btrfs:
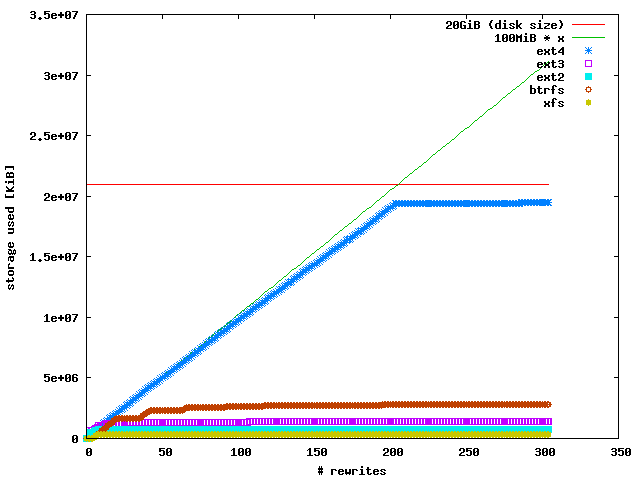
xfs, ext2, and ext3 behaved as I expected. They ended up using 316 MiB, 701
MiB, and 1351 MiB, respectively. btrfs used up to 2763 MiB, presumably because
it's a copy-on-write filesystem. It didn't allocate this space at once, but
allocated some blocks in a linear manner and then stalled for a while. ext4
was a surprise. It grew almost linearly and capped at 19 GiB, or 93% of the
disk's size. While this may be well suited for solid state disks without TRIM
support, it is not for rotating disks which show a higher latency and lower
throughput on the outermost regions.
I took a closer look at ext4 and did 5 additional tests. I
- deleted the file after every write (ext4 + rm)
- called sync to flush all dirty pages from the buffer cache after
every write (ext4 + sync)
- unmounted and remounted the filesystem after every write (ext4 + unmount)
- unmounted and remounted the filesystem after every 50 writes (ext4 +
unmount50)
- unmounted and remounted the filesystem after every 50 writes and increased
the filesize by 100 MiB every 100th write) (ext4 + increase50)
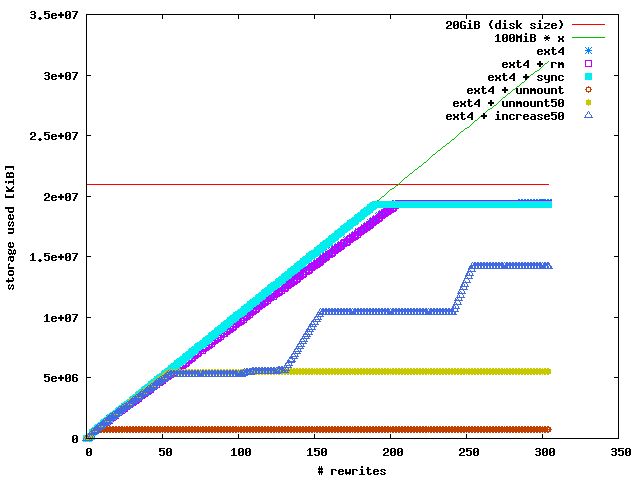
There was no difference between the ext4 + rm test and the normal ext4 test.
However, syncing after every write let the filesystem grew in a perfectly
linear manner as if the file wasn't overwritten. This capped at 92% of the
disk's size. Unmounting after every 50 writes let the filesystem grow until
the 50th write. The ext4 + unmount50 test displayed the same behavior, whether
the filesystem was unmounted after the very first write or not until the 50th
write. Finally, the ext4 + increase50 test made me think that this behavior is
a feature (or bug) of the in-memory free block management. Maybe ext4 can't
reuse free blocks as long as it doesn't hit the size of the underlying disk or
until you unmount and remount the filesystem.
Last but not least I installed FreeBSD and played with UFS2:
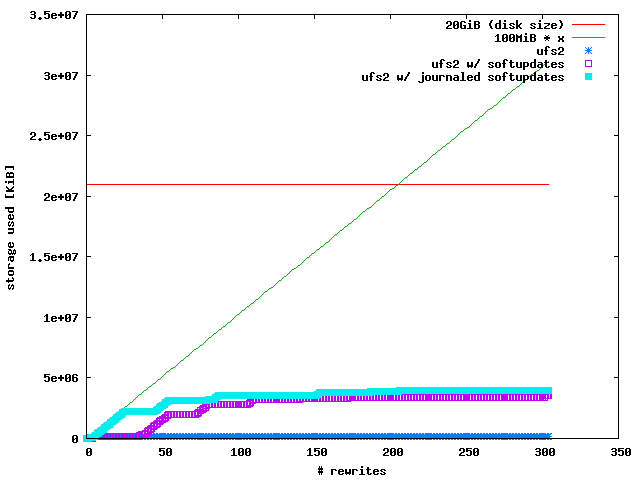
An normal UFS2 filesystem has the smallest overhead in terms of allocated
blocks. It remains constant at 130 MiB when you write a 100 MiB file multiple
times. UFS2 with soft updates remains constant, too, but suddenly allocates up
to 3400 MiB. UFS2 with journaled softupdates behaves in a similiar way,
although it starts to allocate blocks more earlier.
I tested NTFS in 4 ways:
- mbr partiton type and quick format
- mbr partiton type and normal (full) format
- gpt partiton type and quick format
- gpt partiton type and normal (full) format
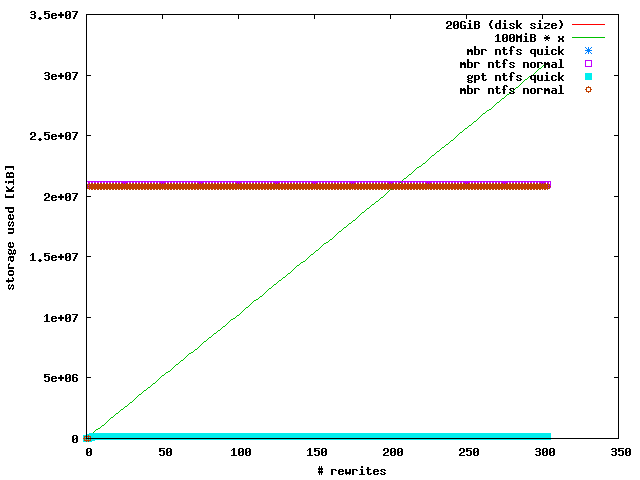
NTFS behaves constantly in all 4 tests. If you do a quick format, it allocates
190 MiB and 191 MiB on a mbr and gpt partitioned disk, respectively. A normal
format allocates almost all available blocks immediatelly. However, in this
case the difference between a mbr and gpt partitioned disk is larger: 20352
MiB (mbr) vs. 20478 MiB (gpt).
Downloads